CSC 241 Lab 10
Submission: Submit the python or text file that contains all your answers to the submission folder for this lab by the end of the lab. To simplify Drew's (our tutor) work, please include your name and the number of the lab at the top of the file (if you're submitting a Python file, use comments: start the line with a #).
Grading: see the grading criteria for lab assignments.
1. (Dictionary). You have become interested in business and stocks, and started following stock news. In stock quotes, company names are often abbreviated to their so-called ticker symbols. The file nasdaq.txt contains a list of company names, their stock (ticker) symbols and their IPO year in the order ticker name, company name, IPO, separated by tab characters ('\t'). (This file is adapted from data available from Nasdaq.) Here are the first few lines:

So "1-800 FlOWERS.COM, Inc." has ticker symbol FLWS, and had its IPO in 1999.
a) Write a function read_ticker() that reads in the file. Each line consists of ticker symbol, company name, and IPO year (including some n/a). read_ticker() should construct and return a dictionary associating the the ticker symbol (as the key( with the company name and the IPO year (as a pair of values). E.g. see the following examples:
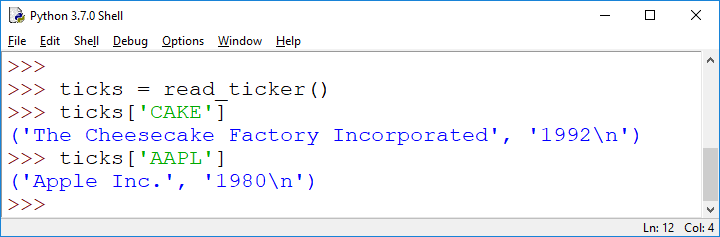
Hint: the fields in the nasdaq.txt file contain " (inserted by Excel, whenever the field contains a comma), be sure to strip the fields: s.strip('"') to remove the " symbol. As the examples above show I didn't strip spaces (the newlines in the years survive), that would probably be a good idea.
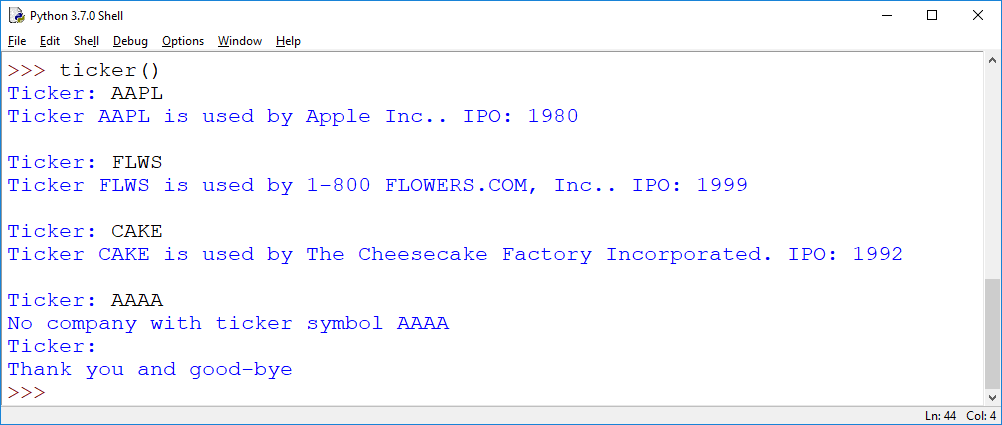
b) Write a function ticker() that first runs read_ticker() and then stores the returned dictionary. It then runs an interactive loop with the user in which the user is prompted for a ticker symbol. If the synmbol is in the dictionary, then the company's name, and the IPO year is printed. Otherwise a warning is printed that the ticker is not in the list. If the user just hits return without entering anything, the loop stops.
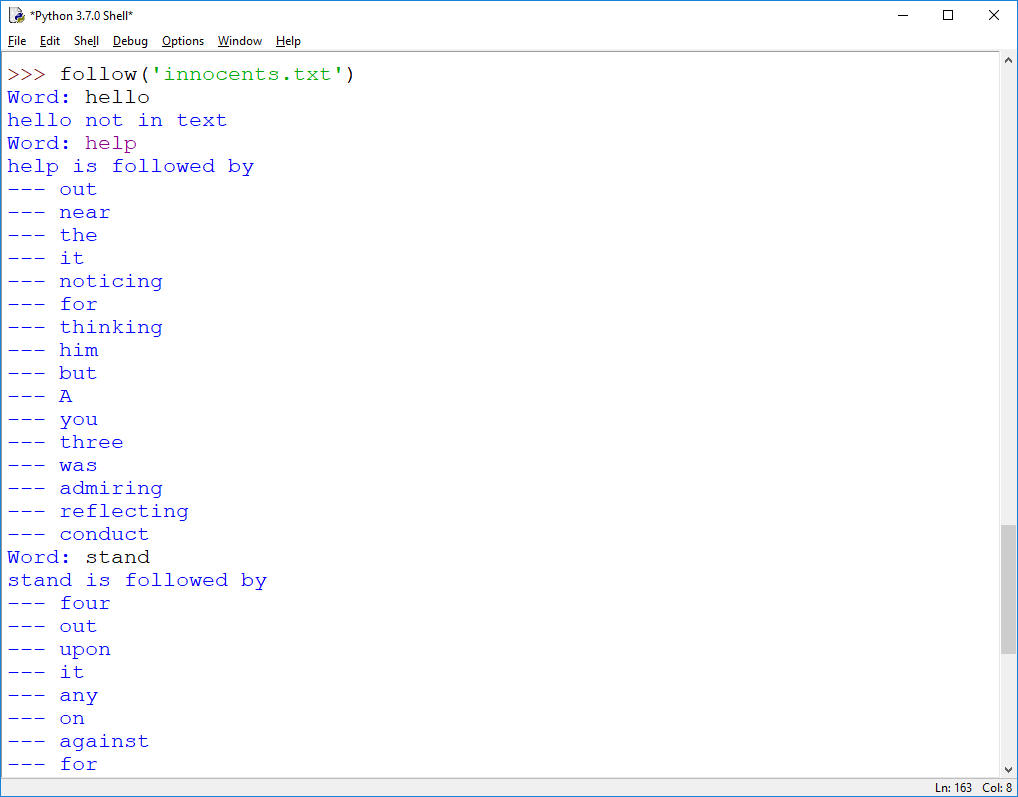
2. (More Dictionaries) You want to analyze which words follow which words in a given text. To that end, implement a function follow(fname) that analyzes the file fname as follows: for every word in the file fname, we create a list of all words which follow it (immediately) in the text. We then start an interactive loop in which the user can enter a word, and we report all the words which follow that word (in the text), or state that the word does not occur in the text (see below for test-run). Note: for better quality result, work with words = split('\W+', text) as we did in the class examples. For that you need to import the split function from the re module.
Marcus Schaefer
Last updated: June 3rd, 2019.