Homework
2 (due 10/1)
CSC 243
We talked about decision patterns (one-sided, two-sided, many-sided, Section 3.2), talked about string methods (Sections 4.1, 4.2), and talked about file input (we'll do file output next), see Section 4.3. We'll continue with general programming patterns (Chapter 5).
If you are working with textfiles on a Mac, do the following: Add
import codecs
at the top of your program, and then instead of open use codecs.open, specifying 'UTF-8' as the encoding scheme):
infile =
codecs.open(name,'r','UTF-8')
In class we also mentioned:
- a breakthrough in quantum computing?
- Benford's Law
- The Monty Hall puzzle. This blew up in 1991,a bit earlier than I remembered. If you don't know it, read it. If you don't believe it, implement it in Python, it's straightforward for you at this point. Believe it now?
- regular expressions, see regular expression tutorial (there's good books on the topic too); Python implements regular expressions in the re module
Submission: The homework is due by midnight (I will not accept late homeworks). You can submit your homework through d2l into the drop-box for this homework.
Please prepare your homework as a single file containing all answers (e.g. doc, docx, or pdf, not a zip file). When submitting programs, include the programs, together with screenshots of test-runs of your program (make sure screenshots are sized so the text is legible; resize and/or crop the images). For an example, see hwexample.docx. How to take screenshots? Check out screenshots for MAC, Windows, Linux. Unless I ask for it specifically, you do not have to submit separate files with program code or executables. If multiple files are necessary, please do not zip them up, just submit them separately.
1. (Reading Assignment) (Re)Read Sections 4.1-4.3. If you want to read ahead, check out 5.1, and 5.2.
2. (Stocks, 15pt) You want to simulate the trajectory of a stock on the stock market. You are using a simple model: the stock has some initial value, init. Every day, the stock goes up or down by a percentage in the range (lower, upper), where that percentage is a random real number in that range (including upper and lower bound). You want to simulate this behaviour for a given number of days.
a) [10pt] Write a function stock(init, lower, upper, days) which simulates a stock with initial value init, and what it's value is after days days. Note that the answer varies, since the percentage increase/decrease each day is a random number in the range (lower, upper), and that number changes each day. A change of per in the value val of the stock is simply calculated as val = val*(1+per/100); for negative per this is a decrease.
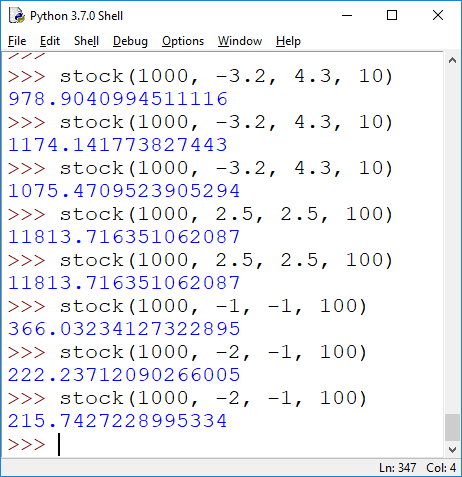
Hint: You can make the problem deterministic by choosing upper=lower which is what I did in some of the examples. That way you can eliminate randomness for testing. The random module supports a function random() which gives you a random number between 0 and 1 (uniformly distributed). Use arithmetic to turn this number into a random number between lower and upper.
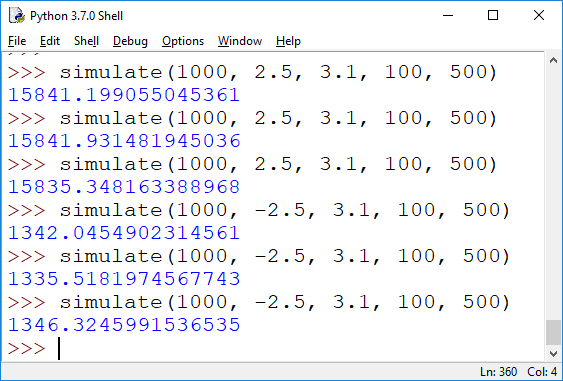
b) [5pt] The stock function runs a single simulation of the stock market; to get better data, you want to repeat the simulation a given number of times and average the outcome. Implement a function simulate(init,lower,upper,days,repeat) that runs the stock() function repeat many times, and returns the average outcome. If you had trouble implementing the stock() function, define stock as return init*(1+random()/100)**days. (This is not the correct answer for a).
3. (Finding Words, 15pt) We wrote a program find_word(word, fname) that prints all lines in a file which contain a specific word. Start with the basic version of that (I started with the first version included in week3.py), and modify it to implement a function find_words(words, fname) which finds all lines that contain any of the words on the list words. When reporting the line, include the information which words were found in the line. See below for a test-run (with default value fname = 'innocents.txt' which you can find in the week 2 content on d2l). If you are on a Mac, read intro text at top on use of codecs.
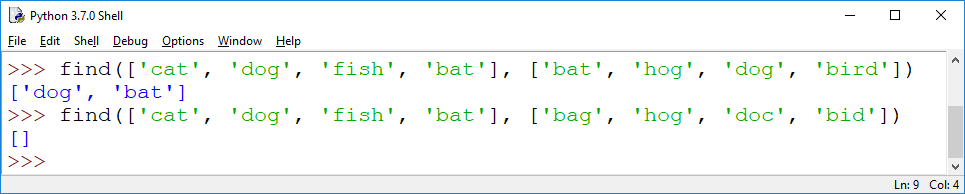
a) [6pt] Implement a function find(words1, words2) which returns a list of all words in the list words1 that also occur in the list words2. Do use a loop to implement this function, do not use sets/set intersection or anything similar. Only, if you cannot implement this function yourself, use returns list(set(words1) & set(words2)) for use in the following problems.
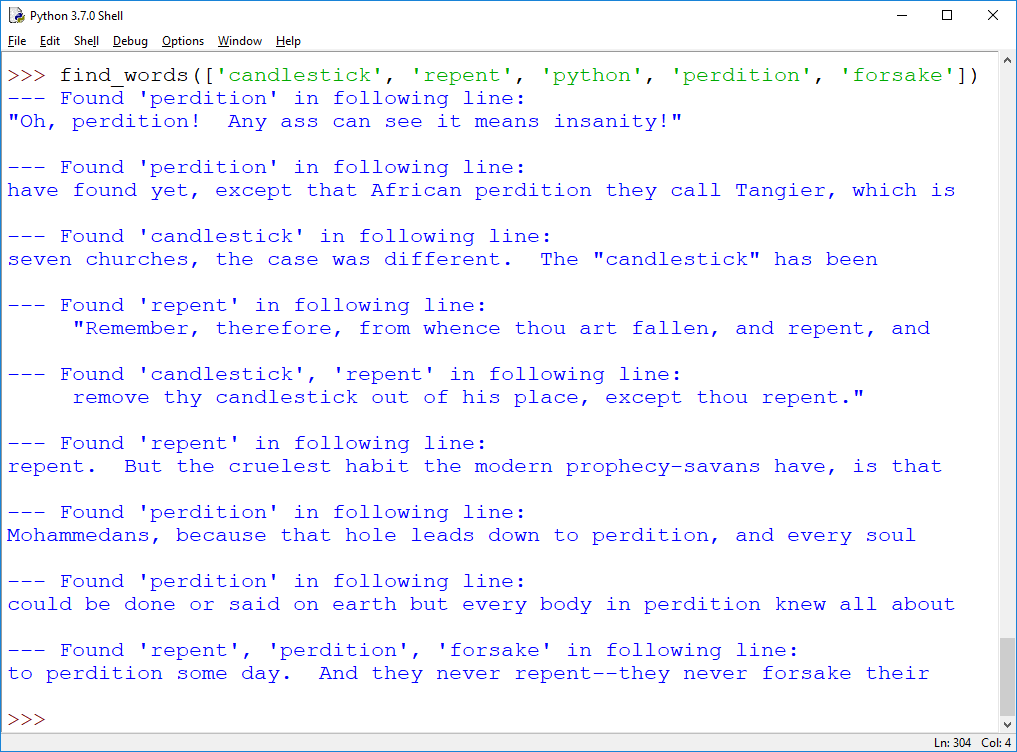
b) [9pt] Using the find function from a), implement find_words. In the output, it is ok, if you show the words that were found as a list, e.g. "Found ['perdirion'] in following lines:" as opposed to the output I show below, where the brackets are removed.
4. (Nice sequences, 10pt) Here is a nice number puzzle, for more on the puzzle, see this blog post. You are trying to find the longest sequence of numbers so that
-
all numbers are between 1 and 100 (inclusive)
-
no number is repeated
-
every number (except the first) divides the number before it, or is a multiple of it.
A sequence satisfying these properties is called nice. For example, 4, 2, 18, 6, 3 is a nice sequence. 4, 400 is not (violates first condition). Write a program nice(lst) that takes a list lst of numbers and returns True if and only if the sequence it is given is nice.
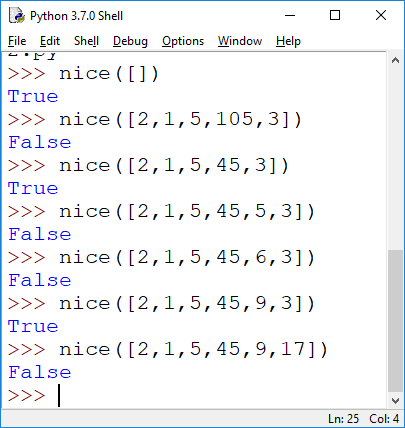
Note: The goal of the puzzle is to find as long a nice sequence as possible (this is not part of your homework, though you're welcome to try). There is a nice sequence of 77 numbers, and that's known to be best possible (there are no nice sequences of 78 numbers). Hint: what type of loop do you need here? Hint 2: There are three conditions. Implement one at a time. Hint 3: no, you don't need a nested loop for testing duplicates, it's easy to get a list of numbers you already encountered.
Marcus Schaefer
Last updated: September 25th, 2019.