Homework
6 (due 10/28)
CSC 401
We talked a bit more about while loops. Couple of links:
- Collatz conjecture:
- Wikipedia entry on Collatz conjecture
- xkcd cartoon
- mathematicians take: Terence Tao on Collatz conjecture
- Turing:
- Wikipedia entry on Halting Problem
- Computerphile on Halting Problem
We then went on to dictionaries (6.1), tuples and sets (6.2), I mostly skipped character encoding (6.3). We saw the module random (6.4) and programmed a simple game using randomization. The book contains a very nice worked example, which is more complex than the examples we've seen: a blackjack application (Case Study CS 6 in the ebook), this makes for instructive reading. Next week, we'll talk about functions and the role of functions in programming (7.1), and how encapsulation is implented (namespaces, local, global variables, see Secion 7.2), and exceptions (7.3) and recursion, Chapter 10. You notice that we're skipping Chapters 8 and 9, some of that material you will see later in Java.
Submission: The homework is due by midnight (I will not accept late homeworks). You can submit your homework through d2l into the drop-box.
1. (Reading Assignment) Read Sections 6.1-6.4 of the textbook. If you want to read ahead, read 7.1-7.3.
2. (Compounded Interest, 10pt) You want to see how many years it takes to turn a starting capital into a target amount if every year you earn interest at a fixed rate. Write a function years(start, target, rate) that determines the number of years needed to turn start into target or more, if every year we earn rate percent. Do this by simulating the interest compounding process using a while loop (I know that the problem can be solved using logarithms, don't). Here are some sample runs:
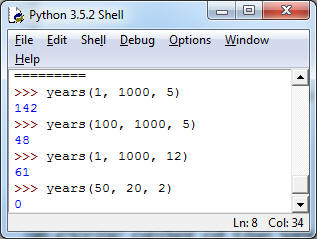
Take the first line: If we start with $1, then after 142 years in which we earn 5% each year, we will have $1000 or more.
3. (Scoring, 10pt) Implement a function SSN() which allows the user to enter the Social Security Numbers of employees at a company by name (do not use real data for testing!). The program will keep prompting the user for a name. If the employee does not have a SSN on record, the program will then ask for the SSN, and store that information. If the employee already has a SSN, the program will display it, and ask for confirmation whether a new SSN should be assigned (and, if so, allows a new SSN to be entered). When the user enters returns, the program prints a report listing all employees with their SSN.
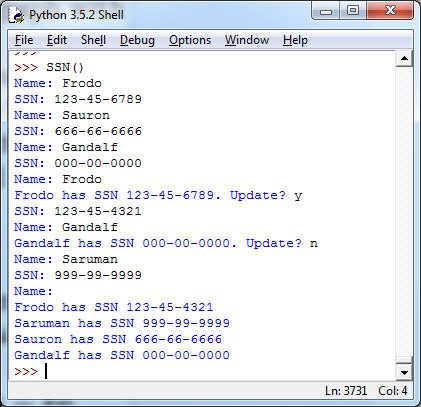
Hint: As usual, build step by step. Your report does not have to be in alphabetical order, however, if you do want to make it alphabetical, you can use sorted on the keys() of your dictionary.
4. (Dictionaries, 10pt) You have a comma-separated file tickers.csv that stores company names and their stock (ticker) symbols. Here are the first few lines (when opened in Excel, you can also use wordpad or notepad, or any other text editor):

So ticker symbol AAPL stands for Apple Inc., and ADBE for Adobe Systems Incorporated.
a) [5pt] Write a function read_ticker() that reads in the file and stores ticker (key)/name (value) in a dictionary and returns the resulting dictionary, so we can look up what a particular ticker symbol means when reading the business news. For example:
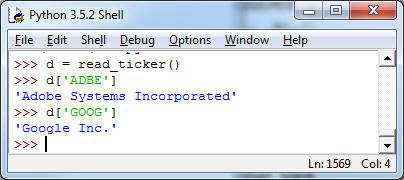
Remove double quotes (") and newline characters ('\n') from the names before storing them as values in the dictionary.
Hint: Every line contains a ticker symbol followed by a comma, followed by the name of the company (use a text-editor to open the file to see this). So you can simply split by comma (now reality is more complicated: the company names often contains commas themselves, in which case Excel will store the cells surrounding by double quotes; to avoid this complication, I cleaned the data by removing all commas beforehand; e.g. Apple's official name is Apple, Inc., not Apple Inc.).
b) [5pt] Write a function tickers() that first runs read_ticker() and then stores the returned dictionary. It then runs an interactive loop with the user in which the user is prompted for a ticker symbol. If the ticker symbol is in the list, then the corresponding company name is printed. Otherwise a warning is printed that the ticker symbol is not on the list. If the user just hits return without entering a name, the loop stops.
Here is a test-run for tickers():
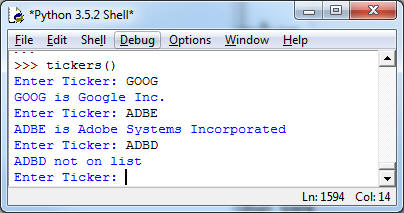
5. (Indexing, 10pt) Do exercise 6.27 (page 197) of the book. Instead of raven.txt use leaves.txt (taken from Project Gutenberg). Here is a test-run:
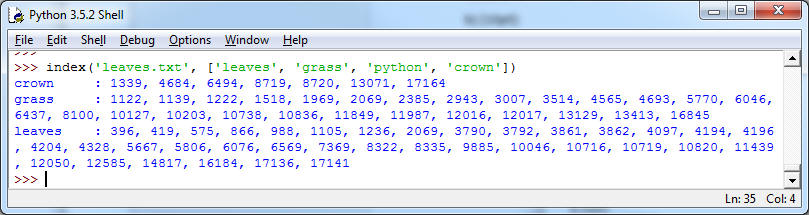
Note a couple of things: page numbers are separated by commas, but they are not printed as lists (no brackets). In a first step, you may just want to accumulate the numbers in lists, and then create a string that contains the numbers without the brackets (this could be a separate function). Words that do not occur in the book are not listed (e.g. python).
Hint: Use a dictionary to store results, like the dictionary of counters we saw. To get the line number, you need an indexed loop through the lines in the text.
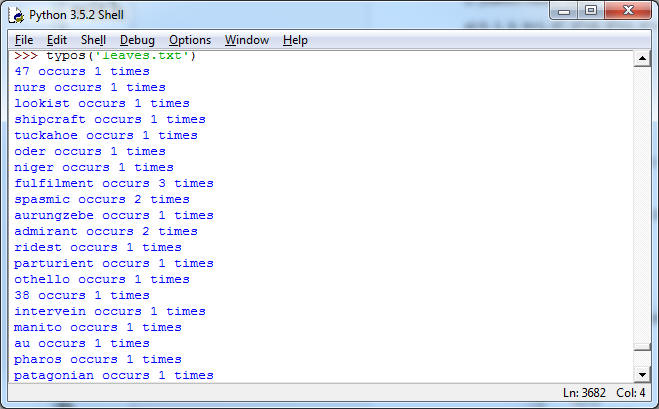
6. (Extra Credit, 10pt) Write a function typos(fname) that finds suspected typos in the file fname. To do that we need a dictionary, for which we use the file words.txt which is a reasonably complete list of English words (though you may disagree after running it on some sample texts). Any word in fname that is not in the dictionary should be printed, and we should be told how often it occurs in fname. Below I ran leaves.txt to test the program; the actual output is much longer. Note: For full credit, do the pre-processing properly: remove any non-letter characters from the input text. Also, each suspected typo should be printed only once. Use the right data-type for that. Do worry about efficiency, i.e. rereading or reprocessing the files is too slow.
Marcus Schaefer
Last updated: May 12th, 2017.